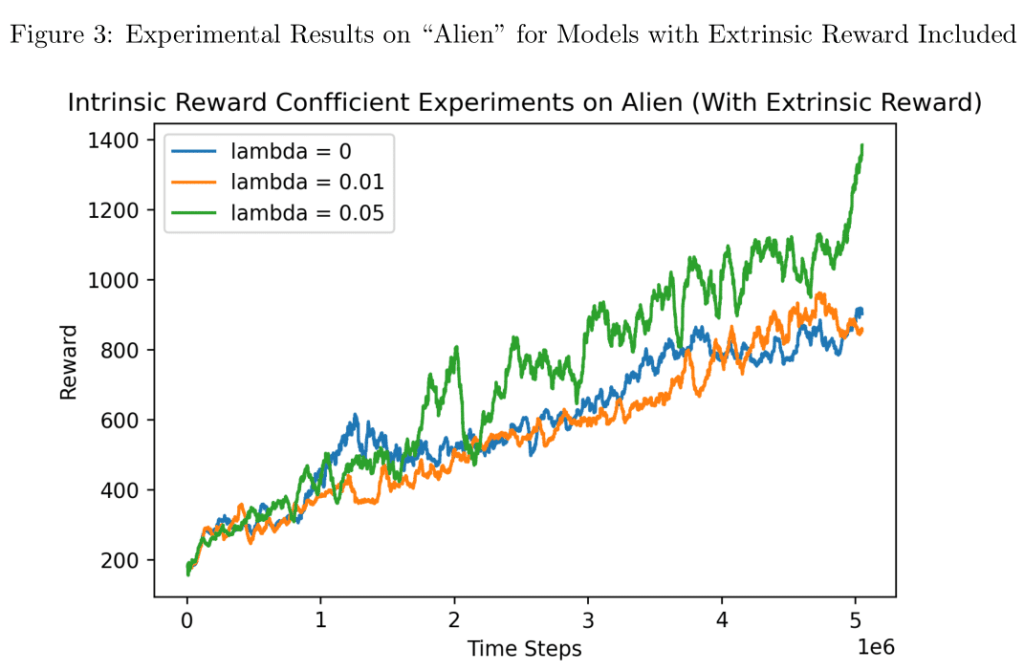
This project was completed for the final project of “CSE 5820: Advanced Machine Learning” at UConn. At the time I was, and still am, interested in the idea of reinforcement learning agents who can learn to complete tasks out of “curiosity” rather than as a result of pure, Skinner-esque reinforcement. The project is a surface level exploration of the topic, but allowed me to become more familiar with popular reinforcement learning libraries like OpenAi’s Baselines and Gym.
The project is heavily based upon “On Learning Intrinsic Rewards for Policy Gradient Methods” (Zheng Et al.) (link) and primarily performs additional experiments using the code base that was developed for the paper.

Leave a comment