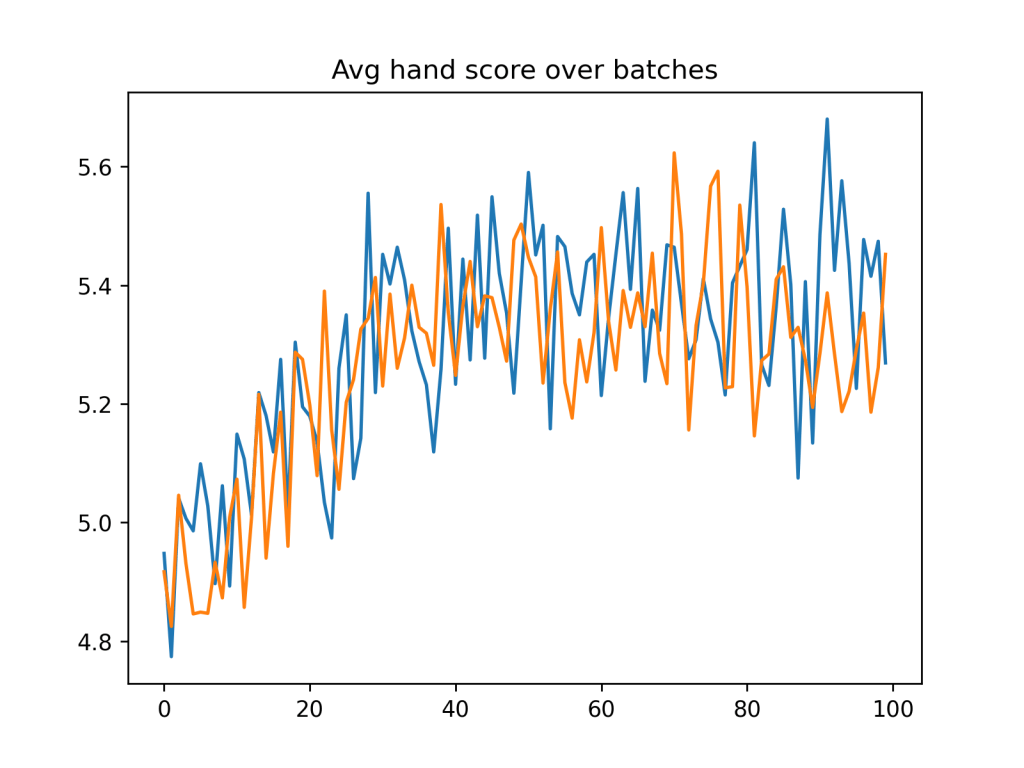
Cribbage is a game that my mother, my grandparents, and I play fairly regularly, thus it made sense to try and explore the world of reinforcement learning through the lense of cribbage. This project was my first real stab at reinforcement learning, and is thus has some room for improvement (as seen by the noisy plot above). In spite of this, I was able to train an agent to play cribbage to a reasonable level, making smart decisions throughout all phases of the game.
All the code is written in python by myself. I created the code for running an instance cribbage as well as the code for training different agents to play the game. This involved 4 primary agents: one to predict the value of a hand given their choice of 4 cards, one to predict the value of a crib given their choice of the remaining 2 cards, one to predict the value a hand in the “play” phase given their choice of 4 cards, and one to decide which card to play in the “play” phase of the game.
These 4 agents are all combined into one larger agent which, first, enumerates all possible hand choices (all subsets of size 4 of a 6 card deal). The agent then approximates the value of each subset by taking a weighted sum of their values according to the three hand evaluating agents (the hand, crib, and play value predictors). Finally the agent chooses the hand which has the highest predicted value.
The remaining agent is used in the “play” phase of the game which is the most complicated phase from a reinforcement learning perspective. This is because the agent has to learn through adversarial play against another agent, causing both to optimize problems which are constantly changing.
Each agent learns through Temporal Difference learning as explained in “Reinforcement Learning: An Introduction” (Sutton and Barto) with a decaying epsilon value. Additionally, instead of representing the game in a full tabular form (which would require a table of 270,725 values for the hand value predictor alone), the table is instead approximated using a Neural Network for each agent.
The usage of Neural Networks in this context was something I had never worked with before when starting this project, so there are possibly some flaws in the way they are implemented into the system. The agents are able to learn how play the game, however, as seen in the example gameplay below.
An Example Hand of Play:
Hand Choosing Phase:
(Player 2 has the crib)
Player 1 Delt: A of clubs, 4 of clubs, 6 of diamonds, 9 of hearts, 10 of diamond, Queen of clubs.
Player 1 Chose: 6 of diamonds, 9 of hearts, 10 of diamonds, Queen of clubs.
(An interesting decision, although this deal does not have a clear best option)
Player 2 Delt: 3 of clubs, 4 of spades, 6 of hearts, 7 of diamonds, 8 of diamonds, 8 of spades.
Player 2 Chose: 6 of hearts, 7 of diamonds, 8 of diamonds, 8 of spades.
(A very wise decision, this scores player 2 at least 12 points)
“Play” Phase:
Player 2 Hand: 6 of hearts, 7 of diamonds, 8 of diamonds, 8 of spades
Current Stack: (Empty)
Card Chosen: 6 of hearts
(A reasonable choice, all choices here have equal risk, but playing an 8 has the highest likelihood of future success.)
Player 1 Hand: 6 of diamonds, 9 of hearts, 10 of diamonds, Queen of clubs
Current Stack: 6 of hearts
Card Chosen: 9 of hearts
(A very smart choice, playing this card scores 2 points for player 1.)
etc …

Leave a comment